ПОСТРОЕНИЕ КОМПЬЮТЕРНОГО ТЕЗАУРУСА С ПОМОЩЬЮ ИДЕОГРАФИЧЕСКИХ СЛОВАРЕЙ
В. И. Антропова
Удмуртский государственный университет
Ключевые слова: тезаурус, идеографический словарь, базы данных
В работе рассматривается задача создания лингвистического ресурса — компьютерного тезауруса — путём использования идеографических словарей. В качестве исходного материала взят идеографический словарь О.С.Баранова. Описывается опыт разработки системы, позволяющей построить компьютерный идеографический словарь автоматизированным путём. Средой использования системы является платформа Microsoft Windows. В качестве модели представления данных выбрана технология реляционной модели баз данных. Системой управления базами данных является MS SQL Server 7.0. Программы обработки данных ориентированы на двухуровневую модель клиент-сервер. Пользовательский интерфейс организован пошаговым исполнением.
1. Введение
Любая система понимания текстов на ЕЯ должна быть снабжена экстралингвистическими знаниями, в частности, знаниями об окружающем мире и о конкретной предметной области (ПО), в рамках которой интерпретируются высказывания [1]. Подобные знания, т.е. отношения между словами на парадигматической оси языка (имеется ввиду как общепринятая лексика, так и лексика конкретных ПО), отражены в идеографических словарях [2]. Сканируя тексты этих словарей, можно выстроить подсистему экстралингвистических знаний в системе понимания.
Основным содержанием сканированного текста (см. рис.1) являются выраженные на русском языке понятия, находящиеся между собой в некоторых семантических отношениях, например: часть-целое, род-вид, множество-элемент и др [3]. В задачи разрабатываемой системы входит идентификация как самих понятий, так и отношений, в которых они участвуют.
Сложность обрабатываемых данных требует присутствия человека на некоторых стадиях создания словаря для сохранения достоверности полученной информации. Поэтому для обеспечения эффективности работы человека предусмотрен удобный пользовательский интерфейс.
Наиболее оптимальной архитектурой системы представляется двухуровневая схема, в которой данные хранятся в центральном хранилище, управляемом некоторой системой управления базами данных (СУБД), и используются клиентским приложением в процессе его функционирования.
В предлагаемой работе в качестве модели представления данных выбрана реляционная модель.
В качестве СУБД выбран MS SQL Server 7.0, удовлетворяющий условиям: характеристики сервера отвечают требованиям, предъявляемым к СУБД масштаба предприятия; отсутствуют нестандартные требования к аппаратуре; имеются удобные визуальные средства для создания и администрирования баз данных, которые значительно упрощают решение основных задач; имеющиеся средства интеграции позволят осуществить непредусмотренное в настоящее время взаимодействие разрабатываемых модулей системы; SQL Server 7.0 функционирует на многих платформах.
21 СТРОЕНИЕ
21.1 ПРОСТРАНСТВО
21.1.1 пространство
t универсум 32 мир чего-л. 49 последовательность 50 вариантность 61
упорядоченное расположение 52
пространство-место распространения чего-л.; среда, определяющая некоторые конструкции.
массив. каре.
i ГЕОМЕТРИЧЕСКАЯ ФИГУРА 89
21.1.2 место
t пространство 86
t где? 20
место-элемент, ограниченная область пространства (где это #?).
местный.
точка.
пункт.
положение-пространственная характеристика.
i эпицентр.
МЕСТО 96 ОБИТАЛИЩЕ 561 РАСПОЛОЖЕНИЕ 95 куда? 110 откуда? 110
21.1.3 область
область-часть пространства (# тела).
район.
зона. зонный, зональный.
участок.
пояс. полоса.
площадь (стрельба по площадям, засеяны большие площади хлебов).
уголок, закуток.
локус. локальный.
i театр (# военных действий). арена (# борьбы, битвы, сражения).
величина 64
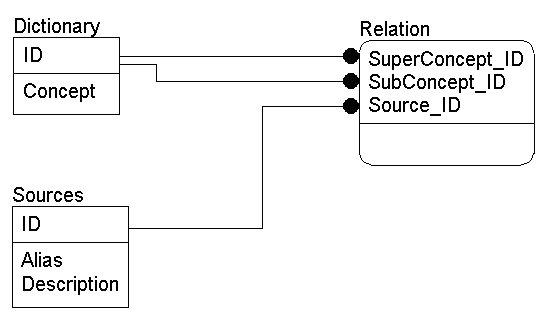
Рис.1. Выдержка из идеографического словаря Баранова О.С.
2. Концептуальная модель
Данные распределены по таблицам таким образом, чтобы можно было удобно и безопасно производить операции над ними, и при этом достигалась достаточно высокая эффективность обработки.
В централизованной таблице (словаре) хранятся все понятия и ссылки на них там, где они образуют отношения. Кроме того, хранятся источники, из которых получены понятия, в другой централизованной таблице, и предоставлена возможность ссылаться на конкретный источник из определенного отношения. Отношения удобно размещать в отдельных таблицах, имеющих идентифицирующие их имена. Все отношения одновременно можно получить с помощью виртуальной таблицы (представления). Для этого вводится зарезервированный префикс имен отношений, а именно “rel_”.
Поскольку заранее трудно предусмотреть все возможные отношения, в которых могут находиться хранящиеся в словаре понятия, предусматривается возможность динамического создания таблиц, представляющих новые отношения.
С точки зрения программ обработки данных, мы ориентируемся на двухуровневую модель клиент-сервер. При таком подходе легче организовать непредусмотренную на этапе проектирования обработку данных, так как это будет производить дополнительное приложение.
3. Построение информационной модели
В качестве инструмента выбран универсальный пакет автоматизированного проектирования БД, позволяющий производить концептуальное моделирование предметной области (ПО) и впоследствии преобразовывать полученную модель в логическую схему базы данных, ориентированную на определенную СУБД. В основе систем такого рода лежит та или иная интерпретация ER-модели. Одним из наиболее популярных программных продуктов в этой области является ERwin (компаниия Platinum). ERwin – средство, в котором сочетаются графический интерфейс, инструменты для построения ER-диаграмм, редакторы для создания логического и физического описания модели данных и прозрачная поддержка ведущих реляционных СУБД.
Процесс построения информационной модели состоит из нескольких этапов. Первый из них - создание логической модели данных: определение сущностей, определение зависимостей между сущностями, задание первичных и альтернативных ключей, определение неключевых атрибутов сущностей. Второй этап – это переход к физическому описанию модели: назначение соответствий имя сущности – имя таблицы, атрибут сущности – столбец таблицы, задание хранимых процедур и ограничений. Последний этап - генерация базы данных.
Процесс создания логической модели данных заключается в визуальном редактировании ER-диаграммы, которая строится из трех основных элементов: сущностей, атрибутов и связей.
Для создания физической модели данных, разработчик выбирает конкретную СУБД и переключается на физический уровень отображения диаграммы. На уровне физической модели сущности соответствует таблица в реальной СУБД, атрибуту – колонка таблицы, связи – внешний ключ (если для связи задавалось имя роли, то оно соответствует имени колонки внешнего ключа в дочерней таблице), первичным и альтернативным ключам - уникальные индексы, а инверсным входам – неуникальные.
Для разрабатываемой нами системы после формализации модели ПО имеем следующую логическую модель (в нотации Erwin):
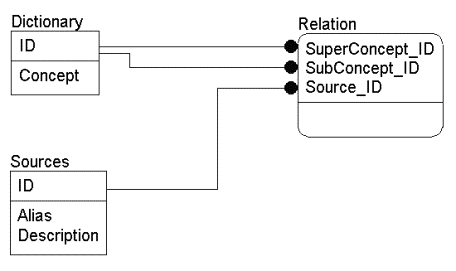
Рис 2. Логическая схема БД
и соответствующую ей физическую модель для MS SQL Server 7.0:
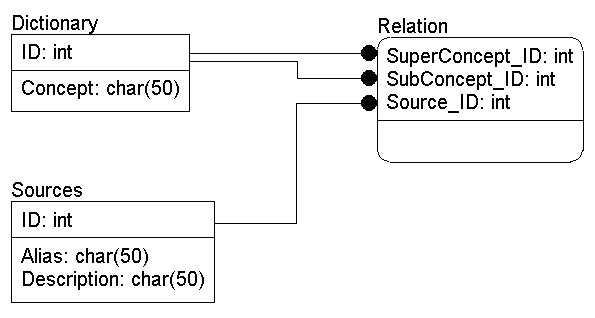
Рис 3. Физическая схема БД
На этапе генерации схемы БД Erwin автоматически создает следующие элементы:
таблицы, уникальные индексы для каждого первичного и альтернативного ключа и неуникальные – для инверсных входов, хранимые процедуры, триггеры для обеспечения ссылочной целостности, другие объекты, необходимые для управления данными.
Результатом работы генератора является следующий сценарий на языке SQL для создания базы данных:
CREATE TABLE Dictionary (
ID int IDENTITY,
Concept char(50) NOT NULL
)
go
ALTER TABLE Dictionary
ADD PRIMARY KEY (ID)
go
CREATE TABLE Sources (
ID int IDENTITY,
Alias char(50) NOT NULL,
Description char(50) NOT NULL
)
go
ALTER TABLE Sources
ADD PRIMARY KEY (ID)
go
CREATE TABLE Relation (
SuperConcept_ID int NOT NULL,
SubConcept_ID int NOT NULL,
Source_ID int NOT NULL
)
go
ALTER TABLE Relation
ADD PRIMARY KEY (SuperConcept_ID, SubConcept_ID, Source_ID)
go
ALTER TABLE Relation
ADD FOREIGN KEY (Source_ID)
REFERENCES Sources
go
ALTER TABLE Relation
ADD FOREIGN KEY (SubConcept_ID)
REFERENCES Dictionary
go
ALTER TABLE Relation
ADD FOREIGN KEY (SuperConcept_ID)
REFERENCES Dictionary
Go
4. Общая схема работы приложения
В последние годы создано немало продуктов для анализа предметной области и построения логической схемы приложения. Один из них- CASE средство Rational Rose, предназначенное для разработчиков, возможности которого основаны на UML. Результатом моделирования в Rose является файл с логической моделью системы. Возможности Rational Rose используются для визуализации некоторых аспектов приложения.
Последовательность шагов преобразования графического изображения страницы идеографического словаря (см. рис. 1) в набор семантически связанных понятий, хранящихся в базе данных, предполагает следующие этапы:
- Перевод сканированного изображения в текстовое представление с помощью программы распознавания и сохранение полученного результата в текстовом файле.
- Разбор текста, полученного на предыдущем этапе, и выделение значимой информации - понятий и отношений между ними. Полученные на этом этапе данные также необходимо сохранить в текстовом файле, чтобы в случае сбоя не повторять процедуру анализа. Такой подход позволяет разделить функции системы и предоставляет возможность использовать дополнительные программы, которые создают данные в подходящем формате. Формат представления идеографической информации в текстовом файле определяется следующим образом. Файл разбивается на три секции:
- Заголовок. Здесь располагается псевдоним и полное название источника идеографических данных.
- Секция определений, где символам, обозначающим отношения в тексте, сопоставляются осмысленные имена.
- Секция отношений. Здесь располагаются тройки вида X Y Z, где X, Z- понятия, а Y- символ отношения.
Тест_1, Идеографический Словарь Баранова
#
i, rel_Род-Вид
v, rel_Синонимы
w, rel_Антонимы
#
область i арена
прерывность w непрерывносгь
непрерывность v беспрерывность
##
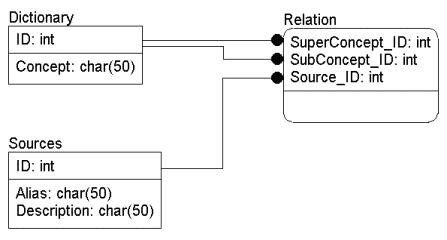
Рис 4. Пример файла с идеографической информацией
- Проверка полученных результатов оператором и их подготовка к сохранению в базе данных.
- Загрузка данных в базу и распределение по соответствующим таблицам.
Схема, представляющая работу приложения в целом, приведена ниже:
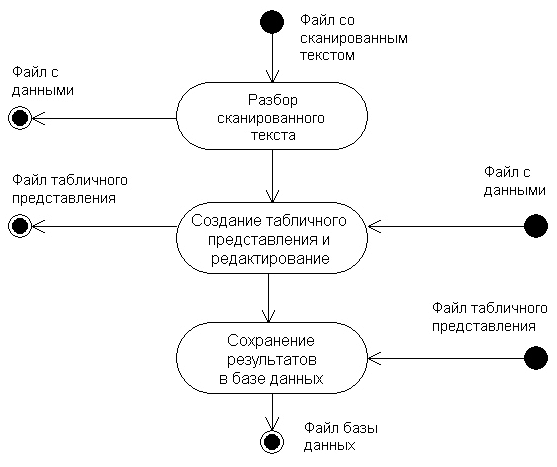
Рис 5. Общая схема работы приложения
Поскольку в системе существует последовательность шагов, пользовательский интерфейс организован пошаговым исполнением - по принципу «Мастера» (Wizards). Так, например, пользователь может увидеть сканированный и разобранный текст,
Рис. 6. Главная форма приложения
табличное представление, базу данных и т.д.
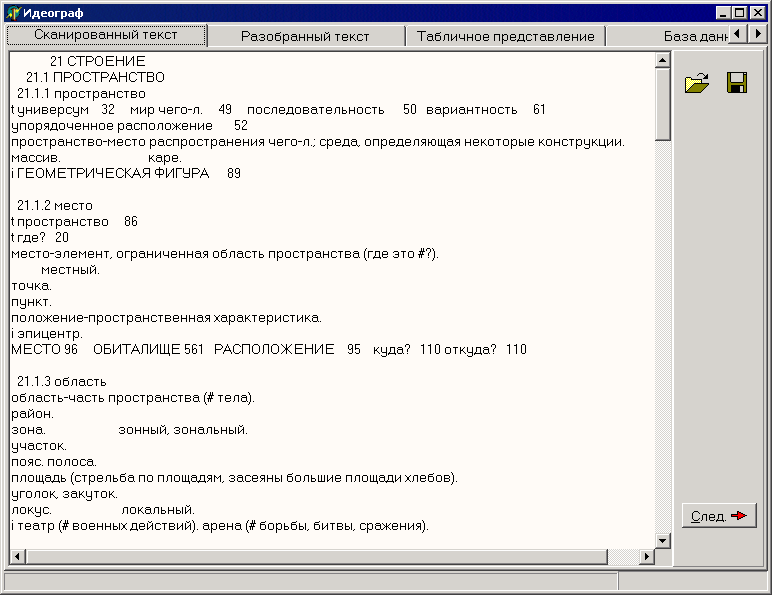
Рис. 7. Запросы
Литература
- Попов Э.В. Общение с ЭВМ на естественном языке. М.: Наука, 1982. 360 с.
- Баранов О.С. Идеографический словарь русского языка. М.:ЭТС, 1995. 820 с.
- Гаврилова Т. А., Хорошевский В. Ф. Базы знаний интеллектуальных систем. СПб: Питер, 2001. 382 с.
Building computer thesaurus using ideograph dictionaries
Valentina Ivanovna Antropova
Keywords: thesaurus, database, ideograph dictionary
The task of creating linguistic resource (computer thesaurus) by using ideograph dictionaries is considered in this article. The ideograph O. N. Baranov’s dictionary is selected as a source stuff. The article describes the experience of developing the system, which allows to build the computer ideograph dictionary automatically. The environment of the system using is Microsoft Windows. The data processing programs are oriented to client-server two level model. The common processing scheme of the existing application is described in the article. The interface created in accordance to “Wizard” principle is organised in a step-by-step manner.