Выделение
фрагментов в текстах при классификации
Markup of text fragments during classification
Васильев В.Г. (vvg_2000@mail.ru)
Институт проблем
информатики РАН
В работе проводится сравнительный анализ подходов к выделению значимых фрагментов в текстах в процессе автоматической классификации. Рассматриваются новые алгоритмы на основе скрытой марковской модели, покрытия текста специальным иерархическим множеством фрагментов и предварительной сегментации текстов.
При решении задач автоматической классификации текстовых данных одной из важных задач является представление и объяснение результатов классификации пользователю. В частности, достаточно важным для понимания причин отнесения текста к определенной рубрике является выделение в нем релевантных ей фрагментов (особенно это актуально в случае классификации политематических документов).
В случае использования лингвистического подхода (т.е. правила отнесения текстов к рубрике описываются с помощью некоторого информационно-поискового языка) такое выделение является достаточно простой задачей, которая решается путем отбора предложений, удовлетворяющих введенному правилу. Однако при использовании статистического подхода к классификации ее решение значительно усложняется. Это связано с тем, что в данном случае документ обычно представляется в виде одного вектора весов информационных признаков для всего текста, а также с отсутствием обучающих массивов с эталонным делением текстов на фрагменты.
Введем
необходимые обозначения. Пусть ![]() рубрики иерархического
классификатора, задающие темы, которые представляют интерес и которые требуется
автоматически выделять в текстах,
рубрики иерархического
классификатора, задающие темы, которые представляют интерес и которые требуется
автоматически выделять в текстах, ![]() – текст на
естественном языке, состоящий из n
предложений,
– текст на
естественном языке, состоящий из n
предложений, ![]() – вектор весов слов в
предложении
– вектор весов слов в
предложении ![]() размерности m, где m – общее число слов в тексте. Требуется для каждой рубрики
размерности m, где m – общее число слов в тексте. Требуется для каждой рубрики ![]() ,
, ![]() определить факт
наличия в тексте информации по ней и в случае положительного решения найти
предложения, ей соответствующие. Иными словами, для рубрики
определить факт
наличия в тексте информации по ней и в случае положительного решения найти
предложения, ей соответствующие. Иными словами, для рубрики ![]() ,
, ![]() требуется найти вектор
требуется найти вектор
![]() , где
, где
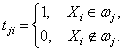
Задача выделения значимых фрагментов тесно связана со следующими классическими задачами анализа текстов:
‑ классификация текстов – определение принадлежности текстов к рубрикам классификатора (в данном случае производится оценка отдельных предложений);
‑ сегментация текстов – разделение текстов на тематически однородные фрагменты (в данном случае производится выделение в тексте групп предложений, относящихся к одной теме);
‑ реферирование текстов – выделение значимых предложений в тексте с целью построения его краткого изложения (в данном случае производится выделение не всех значимых предложений, а только относящихся к определенной тематике).
Основной
сложностью при выделении значимых фрагментов в текстах является то, что в общем
случае оценку принадлежности предложения к рубрике нельзя проводить без учета
соседних предложений. Например, возможна ситуация, когда фрагмент текста X,
состоящий из предложений ![]() , относящийся к рубрике
, относящийся к рубрике ![]() ,
, ![]() при классификации
целиком будет отнесен к данной рубрике, а при классификации предложений
при классификации
целиком будет отнесен к данной рубрике, а при классификации предложений ![]() по отдельности ни одно
из них может быть не отнесено к данной рубрике
по отдельности ни одно
из них может быть не отнесено к данной рубрике ![]() . Также возможна и обратная ситуация, что предложение
. Также возможна и обратная ситуация, что предложение ![]() относится к рубрике
относится к рубрике ![]() , но при рассмотрении вместе с соседними предложениями оно
уже не будет отнесено к данной рубрике.
, но при рассмотрении вместе с соседними предложениями оно
уже не будет отнесено к данной рубрике.
Рассмотрим более подробно методы сегментации текстов, которые являются наиболее близкими по своему содержанию к задаче, решаемой в настоящей работе. Можно выделить следующие основные подходы к их построению:
‑ процедурный подход;
‑ структурный подход;
‑ вероятностный подход;
‑ оптимизационный подход.
Процедурный подход основан на построении правил, учитывающих различные элементы текста: отступы строк, знаки препинания, ключевые слова, референтные связи между словами, а также различные элементы оформления документов (заголовки, разделы, параграфы). Данный подход оказывается эффективным только в том случае, если формат обрабатываемых документов является известным.
Структурный подход основан на использовании различных мер близости между предложениями или фрагментами текста. При этом возможно как вычисление простейших статистик совместной встречаемости слов в различных блоках текста, так и использование методов кластерного анализа. При этом наибольшее распространение получил метод скользящего окна или «перекрывающегося текста» (text-tiling) [2], основанный на нахождении мест в тексте, где мера близости между двумя соседними блоками предложений минимальна. Также интересным является подход, основанный на использовании дивизимного алгоритма иерархического кластерного анализа [3].
Вероятностный подход для сегментации текстов основан на построении различных вероятностных моделей порождения слов в текстах. На практике наибольшее распространение получило представление текстов с помощью скрытых марковских моделей [5, 1]. В частности, в работе [5] рассматривается задача разделения составного текста, представляющего запись передач новостей по радио, на отдельные новостные сообщения. В данном случае открытым состояниям скрытой марковской модели, формальное определение которой будет дано далее, соответствуют отдельные слова в тексте, а скрытым состояниям – позиции слов в отдельных сообщениях, т. е. первым словам каждого сообщения будет соответствовать состояние с номером 1.
Оптимизационный подход основан на задании некоторого показателя качества разделения текста на фрагменты и нахождении такого разделения, которое обеспечивало бы его максимум. В частности, в работе [4] показатель качества зависит от длины фрагмента текстов и степени близости соседних фрагментов текстов. Для нахождения максимума показателя используется алгоритм на основе методов динамического программирования.
Недостатком приведенных подходов к сегментации является то, что при разделении текста на фрагменты в них не учитывается известная информация о тематиках, которые интересуют пользователя (в нашем случае его интересы заданы в виде набора рубрик классификатора). Рассмотрим несколько возможных подходов к решению задачи разметки текстов, которые, с одной стороны, используют идеи, приведенных выше подходов к сегментации текстов, а с другой стороны, лишены указанного недостатка и опираются на использование ранее обученных классификаторов.
Выделение фрагментов путем построения иерархического покрытия текста
Пусть текст ![]() представляется в виде множества
векторов
представляется в виде множества
векторов
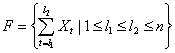 ,
,
где ![]() ‑ вектор весов
слов (словосочетаний) предложения
‑ вектор весов
слов (словосочетаний) предложения ![]() ,
, ![]() - число предложений в
тексте. Данное множество включает в себя множество всех непрерывных фрагментов
(последовательностей предложений без пропусков), содержащихся в тексте. Для
оценки степени соответствия предложения текста рубрике можно использовать
следующие выражения:
- число предложений в
тексте. Данное множество включает в себя множество всех непрерывных фрагментов
(последовательностей предложений без пропусков), содержащихся в тексте. Для
оценки степени соответствия предложения текста рубрике можно использовать
следующие выражения:
![]() или
или
![]() ,
, ![]()
![]()
где ![]() – функция,
осуществляющая вычисление степени соответствия вектора Y рубрике
– функция,
осуществляющая вычисление степени соответствия вектора Y рубрике ![]() ,
, ![]() построенная в
результате обучения некоторого статистического классификатора.
построенная в
результате обучения некоторого статистического классификатора.
Таким образом,
вес ![]() предложения
предложения ![]() ,
, ![]() для рубрики
для рубрики ![]() равен максимальному
(среднему) значению степени близости к данной рубрике
равен максимальному
(среднему) значению степени близости к данной рубрике ![]() всех фрагментов,
содержащих данное предложение. Несложно заметить, что в данном случае для
выделения значимых фрагментов в тексте для каждой рубрики требуется выполнить
классификацию
всех фрагментов,
содержащих данное предложение. Несложно заметить, что в данном случае для
выделения значимых фрагментов в тексте для каждой рубрики требуется выполнить
классификацию ![]() фрагментов, т. е.
вычислительная сложность составляет порядка
фрагментов, т. е.
вычислительная сложность составляет порядка ![]() .
.
Для снижения вычислительной сложности можно воспользоваться представлением текста X в виде следующего иерархически упорядоченного множества векторов фрагментов (иерархического покрытия):
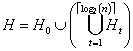 ,
,
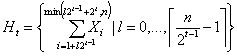 ,
,
![]() ,
,
где ![]() .
.
Несложно заметить, что для мощности множества H справедливы следующие соотношения:
![]() =
=![]()
![]()
Таким образом,
при использовании иерархического покрытия H вычислительная сложность нахождения
степени соответствия текста отдельной рубрике составляет порядка ![]() .
.
Для построенного иерархического покрытия H справедлива следующая теорема, которая говорит о качестве аппроксимации полного множества фрагментов F с помощью множества H.
Теорема. (Об иерархическом покрытии.)
Для любого фрагмента
![]() существует фрагмент
существует фрагмент ![]() такой, что
такой, что
![]() .
.
Доказательство.
Рассмотрим следующие три случая для числа предложений во множестве ![]()
1. Пусть ![]() ,
, ![]() . Тогда
. Тогда ![]() , где
, где ![]() , и существует
, и существует 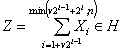 такое, что
такое, что ![]() ,
, ![]() – неотрицательное
целое, т.е. начало фрагмента соответствующего
– неотрицательное
целое, т.е. начало фрагмента соответствующего ![]() расположено не далее
чем в
расположено не далее
чем в ![]() предложениях от начала
фрагмента
предложениях от начала
фрагмента ![]() . Отсюда получаем, что
. Отсюда получаем, что ![]() .
.
2. Пусть ![]() и
и ![]() .
. ![]() , где
, где ![]() ,
, ![]() , и существует
, и существует 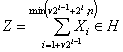 такое, что
такое, что ![]()
![]() – неотрицательное
целое. Отсюда получаем, что
– неотрицательное
целое. Отсюда получаем, что ![]() .
.
3. Пусть ![]() и
и ![]() Тогда
Тогда ![]() , где
, где ![]() , и существует такое, что
, и существует такое, что ![]() ,
, ![]() – неотрицательное
целое. Отсюда получаем, что
– неотрицательное
целое. Отсюда получаем, что ![]() . █
. █
Таким образом, для каждого фрагмента Y из F существует фрагмент из H, который отличаются от него не более чем на половину его длины. В целом схема алгоритма классификации текста принимает следующий вид.
Схема
работы алгоритма на основе иерархического покрытия
1. Построение иерархического покрытия множества предложений текста.
2. Выполнение независимой классификации фрагментов текста с использованием ранее обученного классификатора.
3. Вычисление итоговых весов предложений в тексте путем объединения результатов классификации фрагментов, входящих в покрытие.
4. Отбор предложений, вес которых выше некоторого порога. █
Выделение
фрагментов с использованием скрытой марковской модели
В соответствии с работой [6] скрытая марковская модель с дискретным временем определяется как набор следующих элементов:
![]() – множество скрытых
состояний;
– множество скрытых
состояний;
![]() – последовательность
скрытых состояний;
– последовательность
скрытых состояний;
A –
матрица переходных вероятностей размера ![]() , где
, где ![]() .
.
U – пространство наблюдаемых состояний;
![]() ‑
последовательность наблюдаемых состояний;
‑
последовательность наблюдаемых состояний;
![]() – условные функции
распределения для состояний
– условные функции
распределения для состояний ![]() ,
, ![]()
![]() – вектор начальных
вероятностей скрытых состояний.
– вектор начальных
вероятностей скрытых состояний.
Рассмотрим
теперь как с использованием аппарата скрытых марковских моделей можно
производить выделение в тексте X предложений, соответствующих отдельной
рубрике ![]() ,
, ![]()
В данном
случае пространство наблюдаемых состояний ![]() , где
, где ![]() ‑ размерность
словаря признаков для обучающей выборки, а элементы последовательности
наблюдаемых состояний
‑ размерность
словаря признаков для обучающей выборки, а элементы последовательности
наблюдаемых состояний ![]() ,
, ![]() .
.
Множество
скрытых состояния ![]() определим следующим
образом:
определим следующим
образом:
![]() ‑ предложение
находится внутри фрагмента, соответствующего рубрике
‑ предложение
находится внутри фрагмента, соответствующего рубрике ![]() ;
;
![]() ‑ предложение
находится в начале фрагмента, соответствующего рубрике
‑ предложение
находится в начале фрагмента, соответствующего рубрике ![]() ;
;
![]() ‑ предложение
находится в конце фрагмента, соответствующего рубрике
‑ предложение
находится в конце фрагмента, соответствующего рубрике ![]() ;
;
![]() ‑ предложение не
относится к рубрике
‑ предложение не
относится к рубрике ![]() .
.
Так на этапе
обучения эталонное распределение текста на фрагменты отсутствует, то матрицу
переходных вероятностей ![]() зададим априори. В
данной работе при проведении экспериментов использовалась следующая матрица
зададим априори. В
данной работе при проведении экспериментов использовалась следующая матрица
 .
.
Начальные
вероятности скрытых состояний положим равными друг другу, т.е. ![]() ,
, ![]() .
.
Основную
сложность при построении данной модели составляет задание условных функций
распределения (плотности) ![]() для состояний
для состояний ![]() ,
, ![]() , и вычисление их значений
, и вычисление их значений ![]() . В настоящей работе значения данных функций определяются
следующим образом. Каждому предложению
. В настоящей работе значения данных функций определяются
следующим образом. Каждому предложению ![]() ставятся в
соответствие следующие вектора:
ставятся в
соответствие следующие вектора:
![]() ,
,![]() ,
, ![]()
где b – константа, задающая
размер блока (число учитываемых предложений справа и слева от предложения с
номером i), ![]() – вес предложения с
индексом
– вес предложения с
индексом ![]() ,
, ![]()
![]() ,
, ![]() , t – целое. Отсюда
, t – целое. Отсюда ![]() ,
, ![]() , определяются следующим образом:
, определяются следующим образом:
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Для определения последовательности скрытых состояний используется стандартный алгоритм динамического программирования (алгоритм Витерби [6]), который находит наиболее правдоподобную последовательность из всех возможных. Таким образом, Общая схема работы алгоритма выделения и классификации фрагментов в результате приобретает следующий вид.
Схема
работы алгоритма на основе скрытой марковской модели
1. Выделить предложения в тексте и сопоставить им векторы информационных признаков.
2. Произвести классификацию отдельных предложений с помощью обученного ранее статистического классификатора.
3. С использованием алгоритма Витерби [6] произвести оценивание скрытых состояний цепи Маркова по наблюдаемым состояниям.
4. Произвести разметку текста с использованием найденных скрытых состояний. █
Выделение
фрагментов путем независимой сегментации
В данном случае сначала выделение фрагментов производится путем сегментации текста на тематически однородные фрагменты без учета информации о структуре рубрик классификатора. Затем проводится классификация выделенных фрагментов и отбираются те из них, которые удовлетворяют рубрикам классификатора. В настоящей работе для сегментации текстов было решено остановится на методах, описанных в работах [2] и [3].
В первом
методе, который называется Text Tiling,
сегментация текста проводится следующим образом. Для каждого промежутка между
предложениями вычисляется косинусная мера близости блока из ![]() предложений справа и
слева от него. В резульате формируется вектор
предложений справа и
слева от него. В резульате формируется вектор ![]() размерности
размерности ![]() , где
, где ![]() ‑ число
предложений,
‑ число
предложений, ![]() ‑ размер блока
(в экспериментах использовалось значение
‑ размер блока
(в экспериментах использовалось значение ![]() ). Далее значения вектора
). Далее значения вектора ![]() сглаживаются с
использованием метода скользящего среднего с различными параметрами и находятся
точки локального минимума, которые и используются в качестве границ фрагментов.
сглаживаются с
использованием метода скользящего среднего с различными параметрами и находятся
точки локального минимума, которые и используются в качестве границ фрагментов.
Второй метод основан на использовании иерархического алгоритма кластерного анализа, который последовательно формирует разбиения данных на кластеры, начиная с ситуации, когда в одном кластере содержаться все наблюдения, и заканчивая ситуацией, когда каждое наблюдение образует отдельный кластер. Схема вычислений в данном случае следующая.
Схема алгоритма
сегментации на основе иерархического кластерного анализа
1. Вычисляется
матрица ![]() размерности
размерности ![]() , элементы которой
, элементы которой 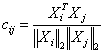 ,
, ![]() .
.
2. Строится
матрица локальных весов ![]() размерности
размерности ![]() , где
, где
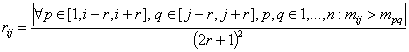 ,
,
![]() ,
, ![]() ‑ константа,
задающая размер окна, в рамках которого вычисляются локальные веса.
‑ константа,
задающая размер окна, в рамках которого вычисляются локальные веса.
3.
Осуществляется рекурсивное разбиение существующих
фрагментов на части, начиная с ситуации, когда все предложения относятся к
одному фрагменту, и, заканчивая ситуацией, когда перестанет возрастать функция
среднего значения внутри-фрагментной близости ![]() , которая определяется следующим образом
, которая определяется следующим образом
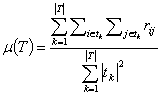 ,
,
где
![]() ‑ множество
фрагментов в тексте. █
‑ множество
фрагментов в тексте. █
В целом схема работы алгоритма классификации фрагментов текста в данном случае принимает следующий вид.
Схема
работы алгоритма на основе независимой сегментации
1. Выделить предложения в тексте и сопоставить им векторы информационных признаков.
2. Произвести разбиение предложений текста на непересекающиеся фрагменты с использованием алгоритма сегментации.
3. Выполнить классификацию выделенных фрагментов с использованием обученного ранее классификатора и отобрать фрагменты, удовлетворяющие хотя бы одной рубрике классификатора.
4. Произвести разметку текста по результатам классификации фрагментов. █
Экспериментальная
оценка эффективности подходов к выделению фрагментов
Для оценки влияния процедур выделения фрагментов на итоговое качество классификации были проведены два эксперимента с массивом нормативно-правовых документов, используемом в рамках семинара РОМИП в 2004 году.
Эксперимент по оценке качества классификации с учетом деления на фрагменты. В первом эксперименте из-за отсутствия эталонного массива с размеченными фрагментами производилась оценка качества классификации текстов целиком с учетом выделения фрагментов различными алгоритмами. Для обучения и оценивания использовались документы, входящие обучающее множество коллекции РОМИП-2004. Данное множество было преобразовано следующим образом. Сначала были отобраны 44 рубрики, содержащие не менее 50 документов. Затем множество отобранных документов было разбито в пропорции 80% на 20% для построения нового обучающего и тестового множеств.
Для классификации текстов использовались метод вероятностной классификации на основе смеси распределений фон Мизеса-Фишера (VMF) и метод на основе машин опорных векторов (SVM). Фрагменты размером менее 4 предложений при классификации не учитывались. Множество рубрик, к которым относится текст целиком, формировалось путем объединения множеств рубрик, к которым были отнесены отдельные фрагменты. Таким образом, в результате классификации текста ему ставится некоторое множество рубрик. Оценка качества в данном случае производится с использованием стандартных коэффициентов точности, полноты и F-меры с использованием микро усреднения.
Результаты оценки качества классификации приведены в следующей таблице. В ней используются следующие обозначения: NONE – классификация без выделения фрагментов; HIER – выделение фрагментов на основе построения иерархического покрытия; HMM – выделение в тексте фрагментов с использованием скрытой марковской модели; TILE – выделение фрагментов путем предварительной сегментации текста с помощью алгоритма Text Tile; DIV – выделение фрагментов путем предварительной сегментации текста с использованием алгоритма дивизимного кластерного анализа. Для каждого метода через запятую приводятся показатели: P – точность, R – полнота, F – F-мера.
Таблица 1. Качество
классификации с выделением фрагментов
|
Метод |
SVM (P, R, F) |
VMF (P, R, F) |
|
NONE |
36%, 60%, 43% |
22%, 78%, 32% |
|
HIER |
29%, 70%, 38%, |
15%, 85%, 24% |
|
HMM |
26%, 67%, 36% |
9%, 91%, 16% |
|
TILE |
30%, 61%, 40% |
15%, 83%, 25% |
|
DIV |
34%, 63%, 41% |
16%, 81%, 26% |
Анализ результатов эксперимента, приведенного в таблице 1 позволяет сделать вывод, что использование практически всех методов выделения фрагментов приводит к повышению полноты классификации, что является следствием рассмотрения большего количества элементов текста. При этом наиболее повышение полноты достигается в случае использовании метода HIER, а наименьшее при использовании метода TILE.
Эксперимент
по оценке качества выделения фрагментов в текстах. Во втором эксперименте
для оценки качества выделения фрагментов было сформировано искусственное
тестовое множество ![]() , элементы которого
, элементы которого ![]() получаются в
результате конкатенации случайного набора из
получаются в
результате конкатенации случайного набора из ![]() текстов из множества
текстов из множества ![]() . В данном случае
. В данном случае ![]() ‑ число текстов
во множестве
‑ число текстов
во множестве ![]() ,
, ![]() ‑ индексы
случайно выбранных с возвращением текстов из множества
‑ индексы
случайно выбранных с возвращением текстов из множества ![]() ,
, ![]() ‑ множество
таких текстов из тестового множества, используемого в первом эксперименте,
которые относятся только к одной рубрике.
‑ множество
таких текстов из тестового множества, используемого в первом эксперименте,
которые относятся только к одной рубрике.
Каждому тексту
![]() ,
, ![]() , была поставлена в соответствие матрица эталонной
классификации предложений
, была поставлена в соответствие матрица эталонной
классификации предложений ![]() и матрица
автоматической классификации
и матрица
автоматической классификации ![]() , где
, где ![]() ‑ признак принадлежности
предложения
‑ признак принадлежности
предложения ![]() к рубрике
к рубрике ![]() ,
, ![]() ,
, ![]() ‑ число классов.
Необходимо отметить, что при формировании данной матрицы предполагалось, что
все предложения из текстов
‑ число классов.
Необходимо отметить, что при формировании данной матрицы предполагалось, что
все предложения из текстов ![]() ,
, ![]() , относятся к одному классу.
, относятся к одному классу.
Для оценки качества выделения фрагментов использовались следующие показатели:
![]() и
и ![]() ‑ точность и
полнота классификации предложений в тексте
‑ точность и
полнота классификации предложений в тексте ![]() для класса
для класса ![]() ;
;
![]() и
и ![]() ‑ средние
значения точности и полноты классификации предложений по всем классам.
‑ средние
значения точности и полноты классификации предложений по всем классам.
В следующей
таблице приводятся результаты экспериментов по оценке качества выделении
фрагментов с использованием двух методов классификации. При проведении
эксперимента использовались ![]() и
и ![]() .
.
Таблица 2. Качество
выделения фрагментов в текстах
|
Метод |
SVM (P, R, F) |
VMF (P, R, F) |
|
NONE |
20%, 23%, 22% |
15%, 46%, 22% |
|
HIER |
62%, 72%, 66% |
22%, 72%, 33% |
|
HMM |
46%, 4%, 7% |
3%, 3%, 3% |
|
TILE |
52%, 57%, 54% |
29%, 72%, 41% |
|
DIV |
51%, 59%, 54% |
33%, 48%, 37% |
Таким образом, можно сделать следующий вывод, что качество выделения фрагментов оказывается на достаточно высоком уровне, учитывая недостатки, которые присущи массиву текстов РОМИП. При этом наилучшие показатели качества выделения фрагментов достигаются при использовании метода на основе иерархического покрытия. При этом использование алгоритма SVM оказывается предпочтительнее.
Заключение
Таким образом, в данной работе рассмотрены подходы к разметке текстов по результатам автоматической классификации, основанные на построении специального иерархического покрытия документов фрагментами, использовании скрытых марковских моделей и сегментации текстов. Проведенные эксперименты показали, что за счет выделения фрагментов в текстах можно повысить полноту классификации.
Актуальной задачей для дальнейших исследований является проведение более подробных исследований по оценке качества определения границ фрагментов в тексте, а также проведение с другими алгоритмами сегментации текста на фрагменты.
Работа выполнена при поддержке гранта Президента Российской Федерации для государственной поддержки молодых российских ученых МК-12.2008.10.
Литература
1. Blei D.,
2. Chua1 T.,
Chang S., Chaisorn L., Hsu W. Story Boundary Detection in Large Broadcast News
Video Archives – Techniques, Experience and Trends // MM’04, October 10–16,
2004,
3. Choi F., Wiemer-Hasting
P., Moore J. Latent semantic Analysis for Text Segmentation // Proceedings of
NAACL'01,
4. Fragkou P.,
Petridis V., Kehagias Ath. Linear Text Segmentation using a Dynamic Programming
Algorithm, 2003. – 8 p.
5. Greiff W.,
Morgan A., Fish R., Richards M., Kundu, A. Fine-grained hidden markov modeling
for broadcast-news story segmentation // Proceedings of the First international
Conference on Human Language Technology Research (
6. Rabiner L.
A tutorial on hidden markov models and selected applications in speech
recognition // Proc. IEEE, 77 (2), 1989. – pp. 257-286.