АЛГОРИТМ ИНТОНАЦИОННОЙ
РАЗМЕТКИ ПОВЕСТВОВАТЕЛЬНЫХ ПРЕДЛОЖЕНИЙ ДЛЯ СИНТЕЗА РЕЧИ ПО ТЕКСТУ
ALGORITHM OF THE INTONATION MARKING OF NARRATIVE SENTECES FOR TTS
SYNTHESIS
Цирульник Л.И. (L.Tsirulnik@newman.bas-net.by), Лобанов Б.М. (Lobanov@newman.bas-net.by), Сизонов О.Г. (Osizonov@yahoo.co.uk)
Объединённый институт
проблем информатики НАН Беларуси, Минск, Беларусь
Описывается алгоритм
синтагматического членения и интонационной разметки повествовательных
предложений, учитывающий позиционные и комбинаторные просодические факторы. Использование
предложенного алгоритма при синтезе речи по тексту позволяет избежать так
называемой «монотонности второго рода».
Введение
В [1] описаны общие принципы синтеза просодических характеристик речи по тексту, реализованные в системе «МультиФон». Первый из блоков подсистемы синтеза просодических характеристик речевого сигнала (просодический процессор), используя языко-зависимые ресурсы и правила, осуществляет анализ и просодическую разметку нормализованного орфографического текста. Анализ и просодическая разметка текста происходит в несколько этапов. На первом этапе осуществляется расстановка сильных и слабых словесных ударений, для чего используется грамматический словарь словоформ, содержащий пометы позиции ударения каждой словоформы, а также правила расстановки слабых и сильных словесных ударений, которые учитывают, в частности, принадлежность слова к знаменательным или служебным частям речи, его положение в предложении и ближайшее окружение. На следующем этапе – этапе объединения орфографических слов в фонетические слова и акцентные единицы (АЕ) – используются списки энклитиков и проклитиков, а также правила объединения в АЕ, которые также учитывают принадлежность «смежных» слов к определённым частям речи. На этапе разбиения текста на синтагмы и установки интонационного типа синтагм – завершающем этапе анализа и просодической разметки – используются правила синтагматического членения текста, согласно которым количество АЕ в синтагме не может превышать некоторого фиксированного количества (например, четырёх). Правила синтагматического членения и определения интонационных типов используют явные маркеры границ синтагм в тексте: знаки препинания, а также неявные, в частности, сочинительные и подчинительные союзы. Выходным данным блока анализа и просодической разметки является текст с пометами позиций ударения, границ фонетических слов и АЕ, а также синтагм с указанием интонационных типов каждой синтагмы.
Данная
работа посвящена описанию алгоритма просодической разметки наиболее частотных
компонентов входного текста – повествовательных предложений. На первом этапе
осуществляется членение текста на предложения, и далее каждого
предложения – на пунктуационные и лексические синтагмы. На втором этапе
реализуется автоматическая маркировка интонационного типа каждой синтагмы.
1. Членение текста на предложения, пунктуационные
и лексические синтагмы
Синтез речи
осуществляется по предложениям, которые характеризуются достаточной степенью
интонационной автономности в тексте и допускают наличие достаточно длительной
паузы между ними (0,5 – 1,5 сек.).
Предложением считается отрезок текста,
ограниченный знаками [.], [?], [?!], [!], [!!!]. Конец предложения может быть
обозначен также знаком […], при
условии, что следующее за ним слово начинается с большой буквы.
Предложением будем считать также заголовок всего текста или его части, в конце
которого знак [.] может отсутствовать. Конец такого предложения обозначим
знаком [*]. Кроме того, в отдельный тип выделяется предложение,
ограниченное точкой в конце абзаца. Конец абзаца обозначим знаком [#].
Индикаторами
членения предложения на пунктуационные синтагмы (ПС) являются
знаки препинания. Пунктуационными синтагмами будем
считать предложение (при отсутствии в
нём знаков препинания) или части предложения, ограниченные следующими знаками:
– точка с запятой
[ ; ],
– двоеточие [:],
– запятая [,],
– тире [ – ],
– открывающая скобка [ (
],
– закрывающая скобка
[ ) ],
– комбинация знаков [,–
].
Таким
образом, если предложение содержит n знаков препинания (включая знак
конца предложения), то оно разбивается на n пунктуационных синтагм (n = 1,2,3,…).
Определённым исключением из этого правила может служить ситуация, когда знак
препинания стоит после сочинительного союза: и, да, но и, так и, а, но,
однако, зато, или, либо, то и др. В этом случае предпочтительнее будет
отказаться от установки синтагматической границы на месте этого знака
препинания, хотя она и допустима для некоторого индивидуального стиля речи.
(1) Пример: “Он быстро вошел и, увидя нас,
внезапно остановился”.
Очевидно,
что пунктуационные синтагмы могут быть различной длины (где под длиной
понимается количество слов). Если длина синтагмы слишком большая (например,
более 4-х слов), то следует убедиться, не содержит ли она некоторые простые
лексические признаки (определённые слова или словосочетания), которые позволили
бы разбить её на более мелкие лексические синтагмы (ЛС).
Экспериментальные исследования [2] показывают, что во многих случаях к
таковым может быть отнесено присутствие следующих лексических признаков:
– соединительного
союза «И».
(2) Пример[1]: «Они посидели / и пошли гулять дальше».
Раздел синтагмы – перед «И».
– разделительного
союза «ИЛИ».
(3) Пример: «Стоит ли нам сейчас пообедать / или
подождать до 3-х часов»? Раздел синтагмы – перед «ИЛИ».
– имён
собственных (ИС).
(4) Пример: «Сегодня певица Алла Пугачёва / решила
выступить в нашем городе». Раздел синтагмы – после последнего из следующих
подряд ИС.
– аббревиатур
(АБ).
(5) Пример: «Возможность победы БНФ / вызывает
большие сомнения».
Раздел синтагмы – после АБ.
– названий
разрядов чисел (РЧ).
(6) Пример: «Два миллиона / десять тысяч
/ сто пять целых / двадцать пять сотых».
Раздел синтагмы – после
каждого РЧ.
– названий
месяцев, слов «час, минута» при расшифровке даты и времени (ДВ).
(7) Пример: «Десять часов / пять минут
/ десятого июня / седьмого года».
Раздел синтагмы – после ДВ.
Указанный
перечень не является полным и может быть расширен в процессе анализа всё более
объёмных текстовых и речевых корпусов.
2. Маркировка интонационного типа
синтагм
Категория повествовательных
предложений характеризуется завершённой интонацией – F
(Finality). Категория распознаётся по знакам: [.], […], [*], [#],
которые определяют её интонационный тип, обозначаемый при обработке текста,
соответственно, символами:
– F0
– интонация «точки» - [.],
– F1
– интонация «многоточия» - […],
– F2
– интонация «заголовка» - [*],
– F3
– интонация «абзаца» - [#].
Кроме
перечисленных выше основных пунктуационных типов интонации завершённости,
реализующихся в последней синтагме предложения, внутри него могут присутствовать
также два дополнительных пунктуационных
типа интонации, характеризующихся различной степенью завершённости:
– F4 – интонация «точки с запятой» – [;],
– F5 – интонация «вводности» – [ )], [,– ],
[–].
Интонация
«вводности» реализуется при условии, что в предложении указанным знакам
предшествовали, соответственно, знаки [(
], [,– ], [ –].
Внутри
предложения могут присутствовать также 4 пунктуационных подтипа интонации,
характеризующихся различной степенью незавершённости: N (Nonfinality):
– N0 – интонация «запятой»- [,],
– N1 – интонация «тире» - [ – ],
– N2 – интонация «двоеточия» - [:],
– N3 – интонация «предвводности»- [( ], [,– ],
[ –].
Интонация
«предводности» реализуется при условии, что за указанными знаками
непосредственно следуют, соответственно, знаки
[ )], [,– ], [–].
В свою
очередь пунктуационные синтагмы могут содержать лексические синтагмы с
интонацией незавершённости следующих 3-х типов:
– N4 – интонация «союза И»,
– N5 – интонация «союза ИЛИ»,
– N6 – интонация лексических синтагм – [ИС], [АБ], [РЧ], [НВ].
Далее, как
само предложение, так и входящие в него пунктуационные и лексические синтагмы
могут содержать неопределённое количество синтаксических синтагм [3] с
характерной для них интонацией незавершенности:
– N7
– интонация синтаксических синтагм.
(8) Примеры[2]:
Возможность
победы БНФ [N6] вызывает большие сомнения[F0].
В
пробирке оказалось 2 миллиона [N6] 350 тысяч [N6] молекул белка[F0].
Сегодня
в 10 часов [N6] 15 минут [N6] 34 секунды[F0].
Он
приехал в четверг [N6] 20-го июня [N6] 7-го года[N6] навсегда[F0].
Время от
времени [N3] – для разрядки [F5] – он вставлял шутки[F0].
Любой
народ [N3], -
говорил он [F5], -
достоин уважения[F0].
Описанные
интонационные типы синтагм показаны на рис. 1.
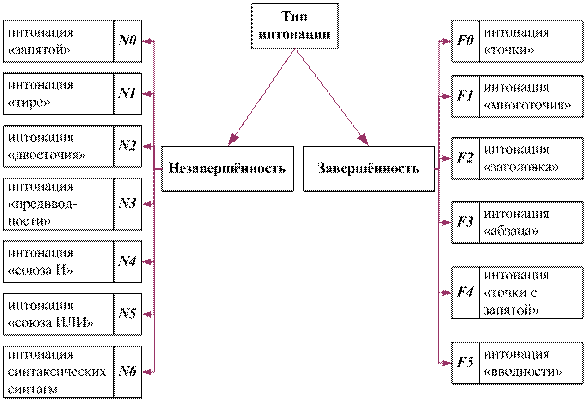
Рис.1. Интонационные типы
синтагм повествовательных предложений
3. Маркировка комбинаторных вариантов
интонационного типа синтагм
Многие из
рассмотренных выше интонационных типов пунктуационных и лексических синтагм могут
иметь определённые комбинаторные
варианты. Это замечание в наибольшей степени касается интонационных
типов N0 [,] и F0 [.]. Причиной возникновения комбинаторных вариантов являются определённые
различия в левом и правом контекстах анализируемой синтагмы, определяемые типом
союзного слова, используемого наряду со знаком запятой для разделения синтагм.
При этом комбинаторные варианты интонационного типа N0 образуются за счёт различий в правом контексте ПС, а F0 - за счёт различий в левом контексте. Запятой и союзом могут
отделяться однородные члены внутри предложения, а также сложносочинённые и
сложноподчинённые предложения. Рассмотрим подробнее особенности возникновения
комбинаторных вариантов интонационных типов N0 и F0.
Можно
выделить следующие основные варианты интонирования синтагм в зависимости от
способа отделения однородных и обособленных членов предложения, а также
сложносочиненных предложений друг от друга:
1. Однородные
члены предложения, отделяемые запятой и следующими за ней соединительными или
разделительными союзами: и, ни...ни, или, либо, ли...ли, то...то, и
др.
Комбинаторный
вариант (0) - N0.0, F0.0.
(9) Примеры:
И пращ
[N0.0], и стрела
[N0.0], и лукавый
кинжал [F0.0].
За
дождем не видно было ни моря [N0.0], ни неба [F0.0].
Гаврила
либо сбежал [N0.0], либо утонул [F0.0].
Стало
совсем темно [N0.0], и улица мало-помалу опустела [F0.0].
2. Однородные
члены предложения, отделяемые запятой и следующими за ней противительными
союзами: а, но, да (в значении «но»), однако и др.
Комбинаторный
вариант (1) - N0.1, F0.1.
(10) Примеры:
На
смелого собака лает[N0.1], а трусливого кусает [F0.1].
Он был
силен [N0.1], да не умен [F0.1].
3. Обособленные
члены предложения, отделяемые причастием.
Комбинаторный
вариант (2) - N0.2, F0.2.
(11) Пример:
Внезапно
он улетел [N0.2], встревоженный вихрем [F0.2].
4. Обособленные
члены предложения, отделяемые деепричастием.
Комбинаторный
вариант (3) - N0.3, F0.3.
(12) Пример:
Длинная
стружка лезла из рубанка [N0.3], завиваясь штопором [F0.3].
5. Сложносочинённое
предложение, отделяемое сочинительным союзом.
Комбинаторный
вариант (4) - N0.4, F0.4.
(13)
Пример:
Гости
уехали [N0.4], и в доме
наступила тишина [F0.4].
6. Сложноподчинённое
предложение, отделяемое подчинительным союзом.
Комбинаторный
вариант (5) - N0.5, F0.5.
(14)
Пример:
Все
заглядывали вперед [N0.5], где качалось красное знамя [F0.5].
Замечание. При отсутствии признаков, определяющих указанные выше интонационные
варианты, второму индексу присваивается значение «6».
(15)
Пример:
Впереди
виднелись горы [N0.6], их вершины блестели [F0.6].
Предложенные
правила маркировки комбинаторных вариантов представлены на рис. 2.
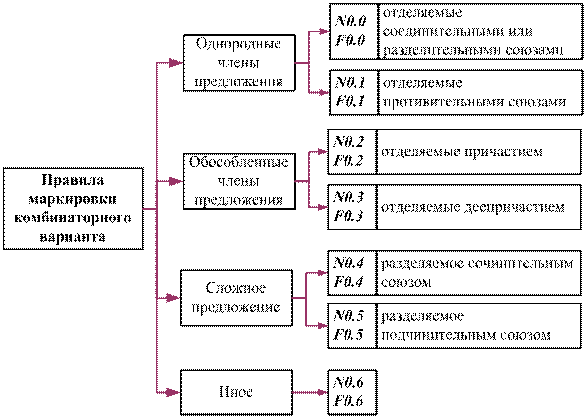
Рис.2. Правила маркировки комбинаторных
вариантов интонационного типа синтагмы
4. Маркировка позиционных вариантов
интонационного типа синтагм
В процессе
синтеза речи особенно важно избежать так называемой «монотонности второго рода». Этот вид монотонности
проявляется при использовании одних и тех же интонационных конструкций для двух
или более идущих подряд синтагм одного интонационного типа. В естественной речи
говорящий, как правило, стремится
избежать такого рода монотонности путём варьирования интонационных
параметров. Это замечание в наибольшей степени касается интонационных подтипов F0.0, N0.0, для которых частота последовательного
появления в текстах весьма значительна.
Определим
минимально необходимый набор позиционных вариантов указанных интонационных
типов.
Позиционные
варианты интонации завершённости – F0.0:
Позиционный
вариант (0)
– F0.0.0, при условии, что этот интонационный подтип встретился в абзаце
впервые или в 3-й, 5-й и т.д. нечётный раз подряд, и так - вплоть до конца
абзаца;
Позиционный
вариант (1)
– F0.0.1, при условии, что интонационный подтип F0.0 встретился в абзаце во 2-й, 4-й, и т.д. чётный раз подряд, и так
- вплоть до конца абзаца.
Позиционные
варианты интонации незавершённости – N0.0:
Позиционный
вариант (0)
– N0.0.0 при условии, что этот интонационный тип встретился в предложении
впервые или в 3-й, 5-й и т.д. нечётный раз подряд раз подряд, и так - вплоть до конца предложения;
Позиционный
вариант (1)
– N0.0.1, при условии, что интонационный тип N1 встретился в предложении во 2-й, 4-й, и т.д. чётный раз подряд, и
так вплоть до конца предложения.
При
необходимости подобным же образом возможно создание вариантов других
интонационных типов, рассмотренных выше.
Предложенные
правила маркировки позиционных вариантов представлены на рис. 3.
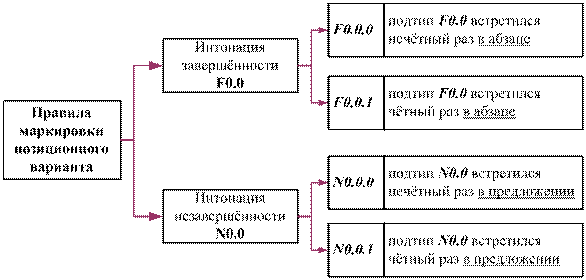
Рис.3. Правила маркировки
позиционных вариантов интонационного типа синтагмы
В общем
случае интонационные тип, подтип, комбинаторный и позиционный варианты каждой
синтагмы в повествовательном предложении обозначаются буквой и следующими за
ней тремя индексами i,
j, k , которые означают
следующее:
– буква
– интонационный тип синтагмы: F (завершённый) или N (незавершённый);
– индекс
i – интонационный
подтип синтагмы: 0, 1, 2, …
– индекс
j – комбинаторный
вариант подтипа синтагмы: 0, 1, 2, …
– индекс
k – позиционный
вариант подтипа синтагмы: 0, 1, 2, …
Заключение
Предложенный
алгоритм позволяет сгенерировать достаточно большое количество вариантов синтагм
завершённого и незавершённого типа, что обеспечивает устранение в
синтезированной речи так называемой «монотонности второго рода».
Рассмотренный
подход к маркировке интонационных подтипов синтагм в повествовательных
предложениях, их комбинаторных и позиционных вариантов может быть использован
также и при маркировке вопросительных и восклицательно-побудительных
предложений.
Доклад
будет проиллюстрирован образцами речи, синтезированной в соответствии с
описанным алгоритмом.
Список литературы
1. Лобанов Б.М. и др. Алгоритмы синтеза просодических характеристик речи по
тексту в системе ”Мультифон” // Компьютерная лингвистика и интеллектуальные
технологии: труды международной конференции Диалог’2007, М.: Издательский центр
РГГУ, 2007. – С. 550-558.
2. Лобанов
Б.М. Алгоритм сегментации текста на синтаксические синтагмы для синтеза
речи // в наст. сб.
трудов Диалог’2008.